本文模型之前的模型都是用一个静态的向量来表示一个entity,与上下文没有关系。而本文最大的贡献在于提出了一种动态表示entity的模型,根据不同的上下文对同样的entity有不同的表示。
模型还是采用双向LSTM来构建,这时实体表示由四部分构成,包括两个方向上的隐层状态,,以及该实体所在句子的最后隐层状态,也就是该实体所在的上下文表示。如图所示。
问题向量的计算与动态实体计算过程类似,这里需要填空的地方用占位符表示。
如果遇到一个entity在document中出现多次的情况,该entity就会有不同的表示,论文中采用CNN中常用的max-pooling方法,从各个表示中的每个维度获取最大的那一个组成该实体的最终表示,这个表示包括了该实体在文章中各种上下文情况下的信息,具有最全面的信息,
计算出实体的动态表示之后,通过注意力机制计算得到问题与每个实体之间的权重,根据语义相近程度选出最可能是答案的那个实体,找到最终的答案。
这里有一个maxpooling的例子,左边是示意图,右边是对应的解释。大家可以先看一下,主要是说明maxpooling的作用。

本文的实验在CNN数据上对模型进行了对比,效果比之前的Attentive Reader好很多,验证了本文的有效性。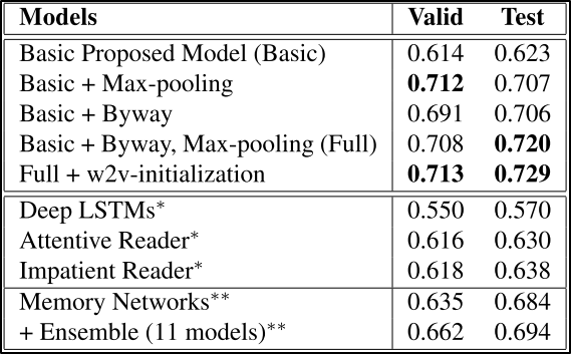
本文模型的一个好玩之处在于用了一种变化的眼光和态度来审视每一个实体,不同的context会给同样的entity带来不同的意义,因此用一种动态的表示方法来捕捉原文中entity最准确的意思,才能更好地理解原文,找出正确答案。实际生活中,我们做阅读理解的时候,最简单的方法是从问题中找到关键词,接着从原文中找到同样的词所在的句子,然后仔细理解这个句子最终得到答案,本文的动态表示正是有意在更加复杂的阅读理解题目上做文章,是一个非常好的探索。


上一篇
 【论文笔记07】End-To-End Memory Networks
【论文笔记07】End-To-End Memory Networks
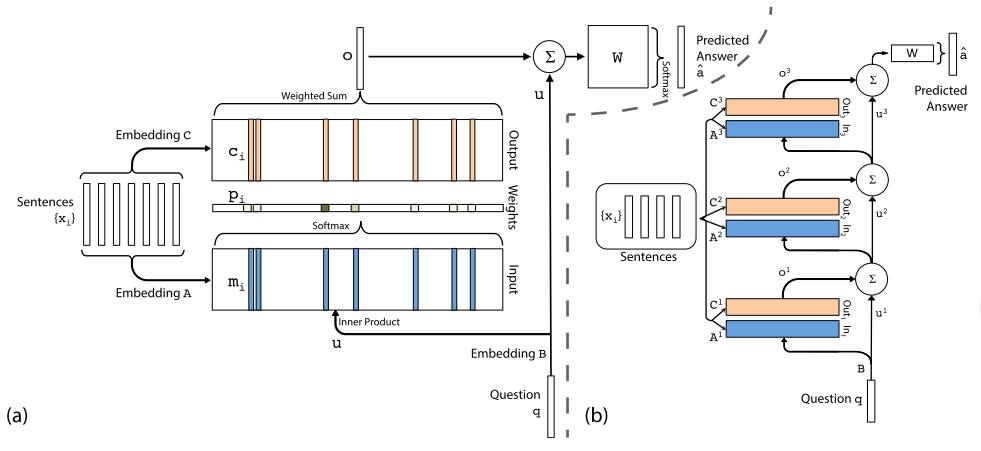
1 背景(1)在记忆网络中,主要由4个模块组成:I、G、O、R,前面也提到I和G模块其实并没有进行多复杂的操作,只是将原始文本进行向量表示后直接存储在记忆槽中。而主要工作集中在O和R模块,O用来选择与问题相关的记忆,R用来回答,而这两部分都
2018-11-17
下一篇
 【论文笔记06】Memory Network
【论文笔记06】Memory Network
1 问题和解决办法(1)问题
当遇到有若干个句子并且句子之间有联系的时候,RNN和LSTM就不能很好地解决;
对于句子间的这种长期依赖,于是需要从记忆中提取信息;
(2)解决办法
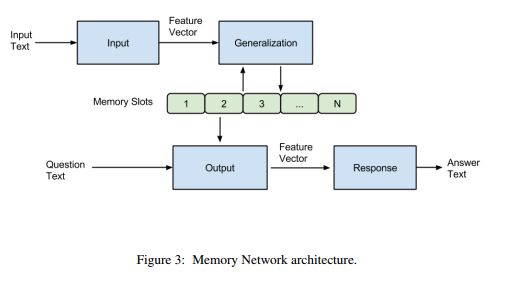
本文提出了实现长期记忆的框架,实现了如何从长期记忆中
2018-11-02